1.概述
索引是存储引擎用于快速找到记录的一种数据结构。在数据量大的时候,索引对性能的影响是巨大的,索引优化是对查询性能优化的最有效的手段,能轻易的将查询性能提高几个数量级。
2.索引的数据结构
索引是存储引擎层面关心的事,不同的存储引擎可以使用不同的数据结构实现索引,总结起来主要有一下几种常见的数据结构:
- B+ 树。
- Hash表(只有Memory引擎支持)。
- R-Tree。
- 全文索引。
3.索引的优点
以下三个优点《高性能Mysql》提到的,很多资料都有提到,关于这三点的个人理解如下:
3.1 减少服务器需要扫描的数据量
这一点很好理解,使用索引能根据sql中索引的列上的条件缩小符合条件的结果集,避免了全表扫描。
3.2 帮助服务器避免排序和临时表
索引中的数据是排序存储的(B+树索引),能对排序有一定的帮助作用,避免在server层有额外的排序工作(explain中Extra列的Using filesort,Using temporary)
3.3 索引可以将随机IO变为顺序IO
这里感觉没有很好的理解,当前能想到的点是如果使用索引覆盖的话,是会把回表的随机io变为顺序io。
4.索引的分类
4.1 按存储类型划分
- 聚族索引 & 非聚族索引
4.2 功能类型划分
- 唯一索引 & 非唯一索引
- 单列索引 & 符合索引
- 全文索引
- 虚拟列索引
5.关于聚族索引 & 非聚族索引
聚族索引描述的是对数据的一种组织方式,如果数据在磁盘上的排列方式和索引的顺序一致,那么这个索引就是聚族索引。相反,如果数据的排列顺序与索引的顺序不一致,那么这个索引就是非聚族索引。
根据聚族索引的定义,一张表最多只能有一个聚族索引。
5.1 聚族索引的优缺点
聚族索引的优点:
- 聚族索引一般将索引和数据存在一起,查找效率高。
- 按索引进行范围查询效率高。
聚族索引的缺点:
- 查找和更新数据的索引列的值,涉及到数据的移动,效率低。(所以尽量以主键增加的方式插入数据,避免主键的修改可以将这个缺点影响降低到最=最小)
5.2 非聚族索引的实现方式
InnoDB的二级索引和MyIsam的索引都是非聚族索引。
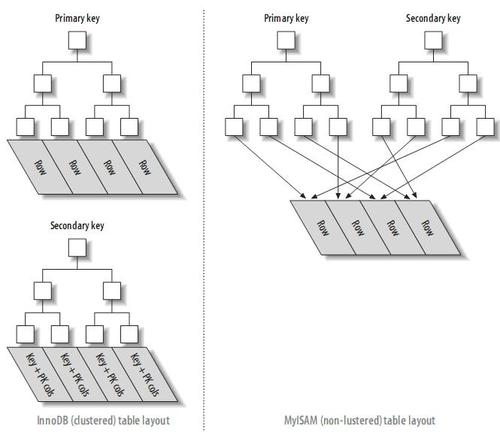
借用《高性能 MySql》书中的图,可以看出区别:
- InnoDB的非聚族索引叶子节点存储的是主键的值。
- MyIsam的非聚族索引叶子节点存储的是具体行数据的指针。
那么InnoDB通过非聚族索引查找数据,还需要回到主键索引再查找一次(这个过程称为回表),MyIsam通过非聚族索引查找数据,最后拿到的是数据的地址,可以直接获取数据。
那么InnoDB的非聚族索引为什么要存储PrimaryKey而不是数据的指针呢?好处是:减少了当出现行移动或者数据页分裂时辅助索引的维护工作。
6.关于InnoDB主键
5小节中提到,Mysql二级索引的查询都有回表环节,都依赖主键聚族索引。
如果表没有索引会怎么样呢?InnoDB存储引擎会按如下方式选择或创建主键:
首先判断表中是否有非空的唯一索引,如果有,则该列即为主键.
如果不符合上述条件,InnoDB存储引擎自动创建一个6字节大小的指针.
7.其它一些索引值得关注的点
- 多列索引的最左匹配原则。
- 多列索引将区分度高的列放在前面。
- 索引覆盖能省去回表步骤,极大的提高效率。
- 合理设计索引为order by服务能提高效率。
- 含有空值的列很难进行查询优化尽量避免,用0、-1、空串代替空值。
- 在列名上使用函数无法使用索引。
- 不要使用大偏移量(limit)。