1.序列化综述
2.1 通用性
技术层面:序列化协议是否支持跨平台、跨语言。如果不支持,在技术层面上的通用性就大大降低了。
流行程度:一方面,很少人使用的协议往往意味着昂贵的学习成本;另一方面,流行度低的协议,往往缺乏稳定而成熟的跨语言、跨平台的公共包。
2.2 强健性/鲁棒性
以下两个方面的原因会导致协议不够强健:
- 成熟度不够,一个协议从制定到实施,到最后成熟往往是一个漫长的阶段。协议的强健性依赖于大量而全面的测试,对于致力于提供高质量服务的系统,采用处于测试阶段的序列化协议会带来很高的风险。
- 语言/平台的不公平性。为了支持跨语言、跨平台的功能,序列化协议的制定者需要做大量的工作;但是,当所支持的语言或者平台之间存在难以调和的特性的时候,协议制定者需要做一个艰难的决定–支持更多人使用的语言/平台,亦或支持更多的语言/平台而放弃某个特性。当协议的制定者决定为某种语言或平台提供更多支持的时候,对于使用者而言,协议的强健性就被牺牲了。
2.3 可调试性/可读性
序列化和反序列化的数据正确性和业务正确性的调试往往需要很长的时间,良好的调试机制会大大提高开发效率。
如果序列化后的数据人眼可读,这将大大提高调试效率, XML和JSON就具有人眼可读的优点。
2.4 性能
性能包括两个方面,时间复杂度和空间复杂度:
- 空间开销(Verbosity), 序列化需要在原有的数据上加上描述字段,以为反序列化解析之用。如果序列化过程引入的额外开销过高,可能会导致过大的网络,磁盘等各方面的压力。对于海量分布式存储系统,数据量往往以TB为单位,巨大的的额外空间开销意味着高昂的成本。
- 时间开销(Complexity),复杂的序列化协议会导致较长的解析时间,这可能会使得序列化和反序列化阶段成为整个系统的瓶颈。
2.5 可扩展性/兼容性
移动互联时代,业务系统需求的更新周期变得更快,新的需求不断涌现,而老的系统还是需要继续维护。如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,而不影响老的服务,这将大大提供系统的灵活度。
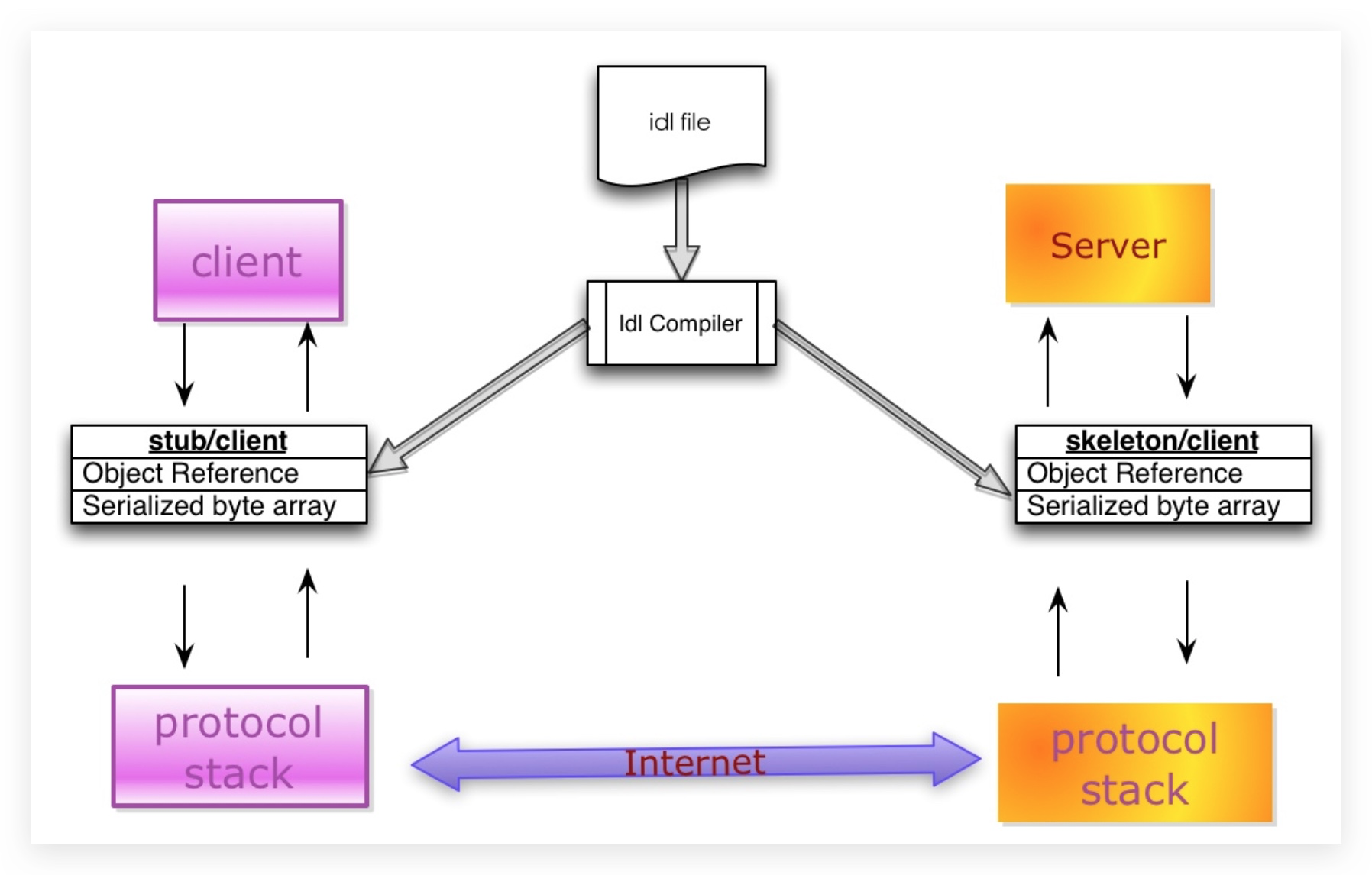
3.序列化协议的组成
典型的序列化和反序列化过程往往需要如下组件:
3.1 IDL(Interface description language)文件
参与通讯的各方需要对通讯的内容需要做相关的约定(Specifications)。为了建立一个与语言和平台无关的约定,这个约定需要采用与具体开发语言、平台无关的语言来进行描述。这种语言被称为接口描述语言(IDL),采用IDL撰写的协议约定称之为IDL文件。
3.2 IDL Compiler:
IDL文件中约定的内容为了在各语言和平台可见,需要有一个编译器,将IDL文件转换成各语言对应的动态库/工作代码。
3.3 Stub/Skeleton Lib:
负责序列化和反序列化的工作代码。Stub是一段部署在分布式系统客户端的代码,一方面接收应用层的参数,并对其序列化后通过底层协议栈发送到服务端,另一方面接收服务端序列化后的结果数据,反序列化后交给客户端应用层;Skeleton部署在服务端,其功能与Stub相反,从传输层接收序列化参数,反序列化后交给服务端应用层,并将应用层的执行结果序列化后最终传送给客户端Stub。
3.4 Client/Server:
指的是应用层程序代码,他们面对的是IDL所生存的特定语言的class或struct。
3.5底层协议栈和互联网
序列化之后的数据通过底层的传输层、网络层、链路层以及物理层协议转换成数字信号在互联网中传递。
4.JDK序列化分析
下面来分析一个序列化实例:
|
|
4.1 序列化内容分析
使用二进制解析软件打开,逐个部分进行分析。
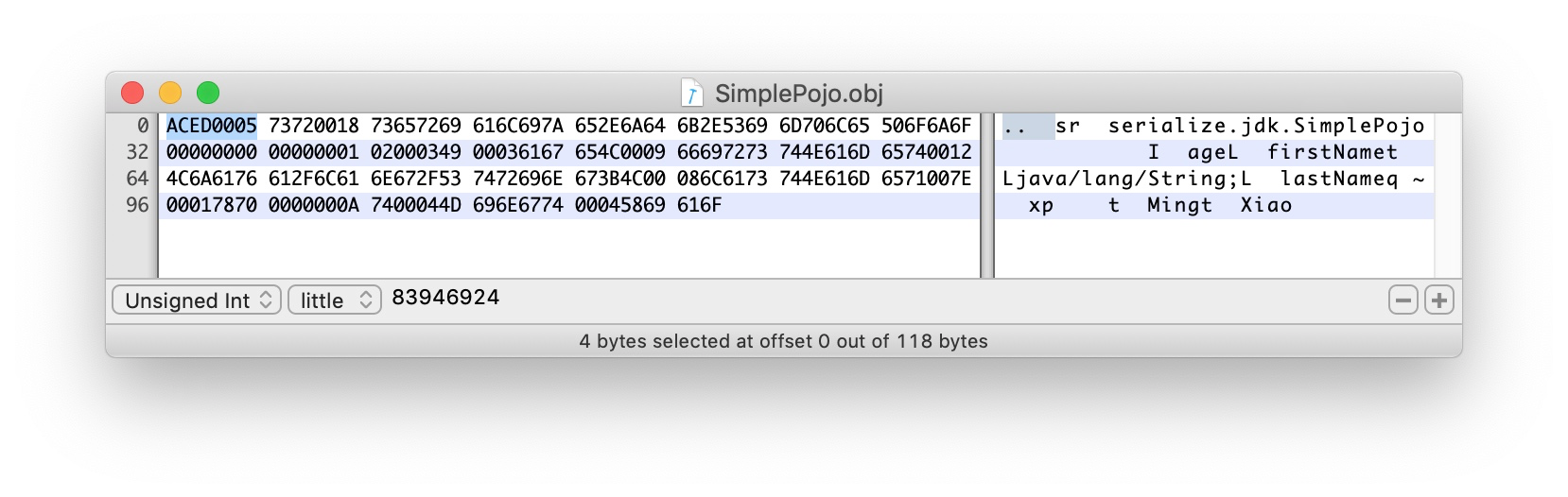
4.1.1 第一部分:
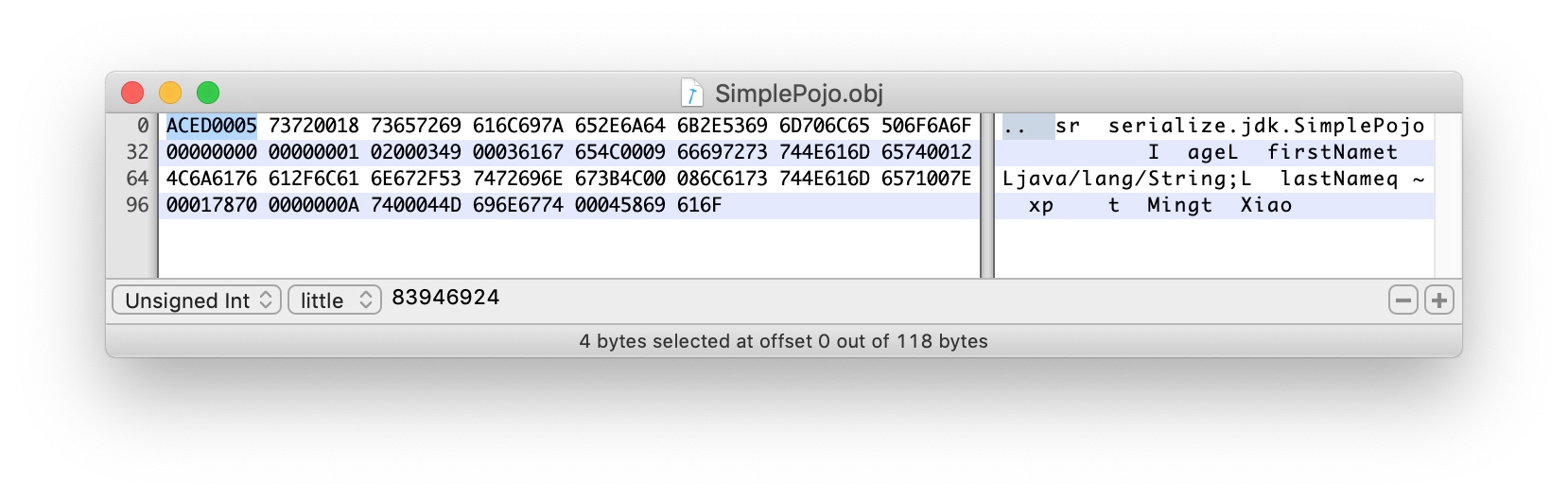
ACED0005:
ACED STREAM_MAGIC 流的幻数,用于标识序列化协议
0005 STREAM_VERSION 标识序列化协议的版本号
参考ObjectOutputStream.writeStreamHeader方法:
|
|
4.1.2 第二部分:
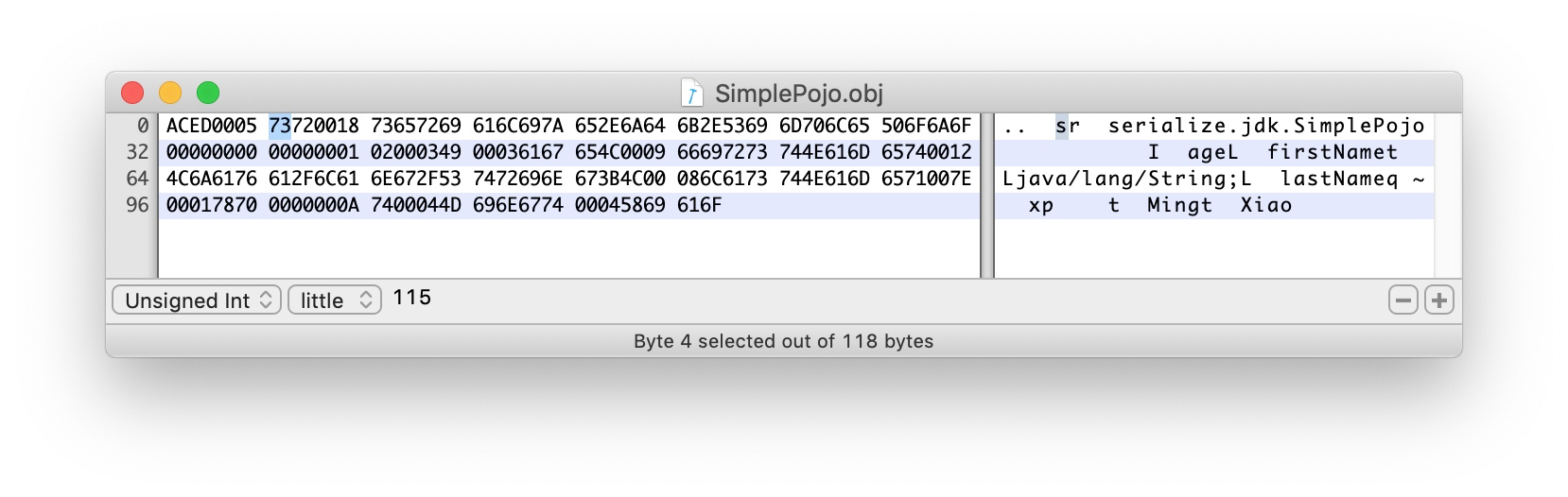
73 TC_OBJECT 表明接下来是一个类
如果是 objectOutputStream.writeInt(123);则不会有这个标示。
4.1.3 第三部分:类描述
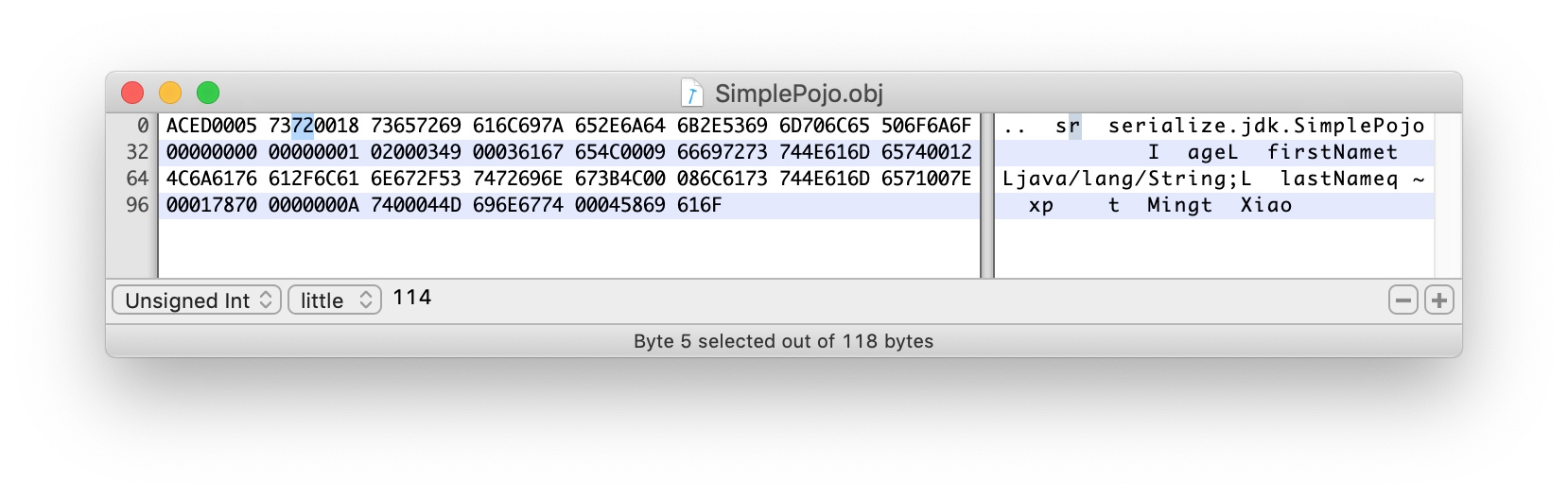
72 TC_CLASSDESC 表明一段类描述开始:
0018 十进制为24,类名长度为24字节
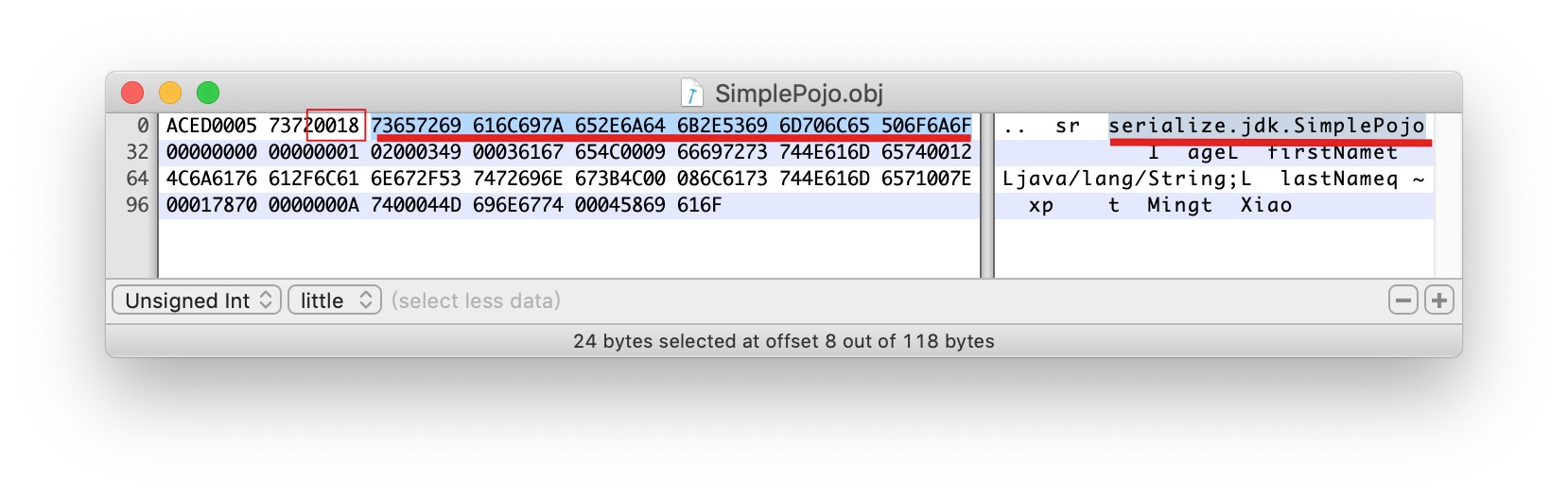
接下来是24个字节的全路径类名 serialize.jdk.SimplePojo
0000 0000 0000 0001 接下来8个字节为serialVersionUID:1
02 Flag 目前只用了5个bit
具体每个位的定义:代码来自 ObjectStreamConstants:
|
|
02表示,只有SC_SERIALIZABLE置为了1,该类实现了Serializable接口。
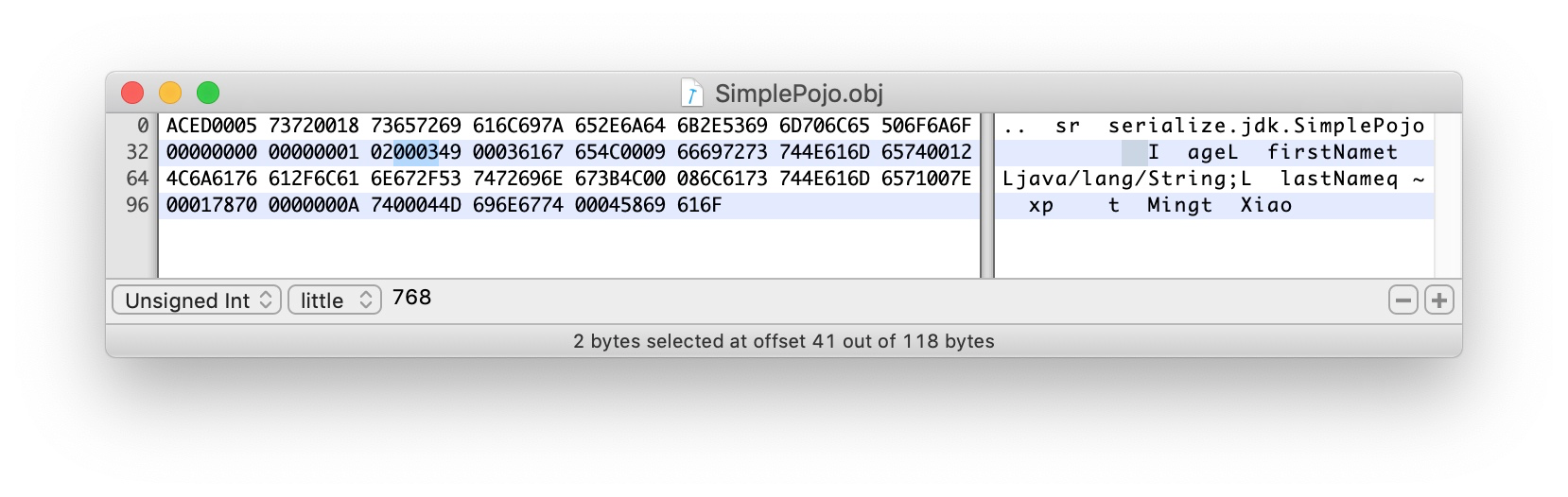
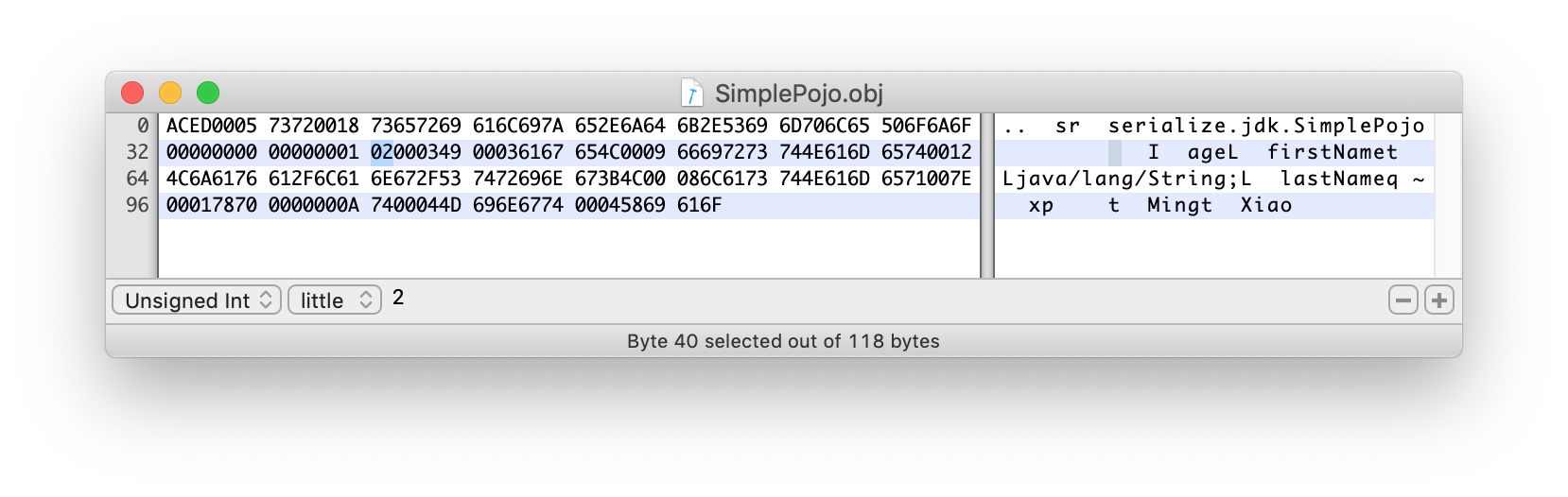
0003 表示该类有3个field(firstName、lastName、age)
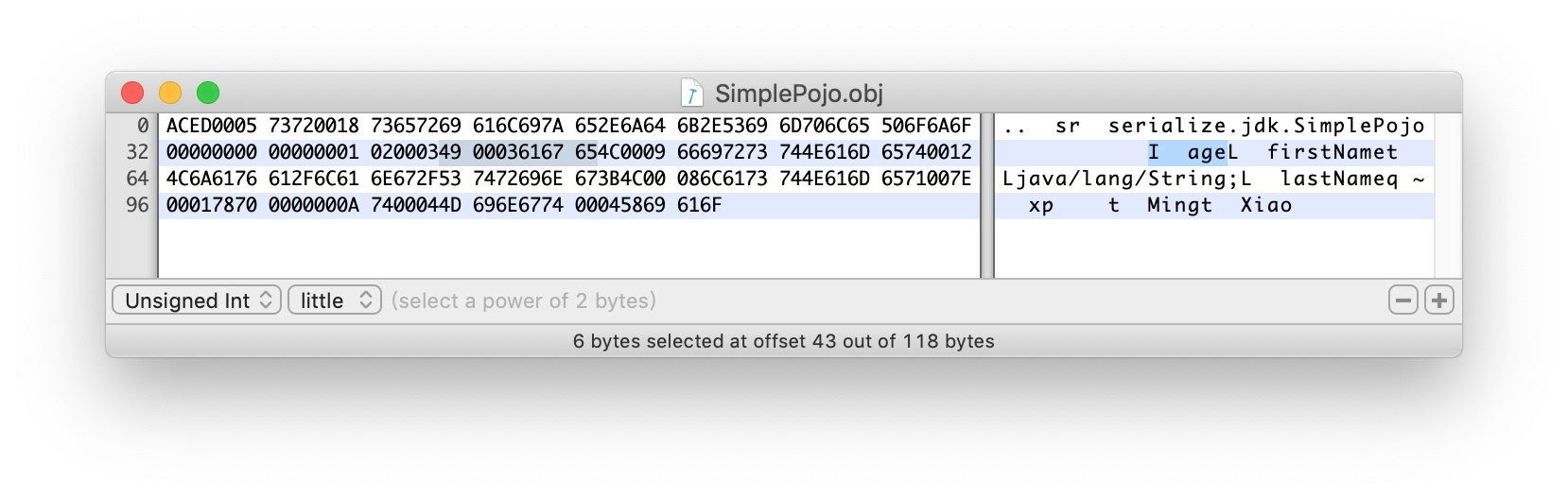
49 0003 616765 描述了第一个filed:
49 - I int类型
0003 字段名长度3个字节
616765 age。
接着是第二个filed:
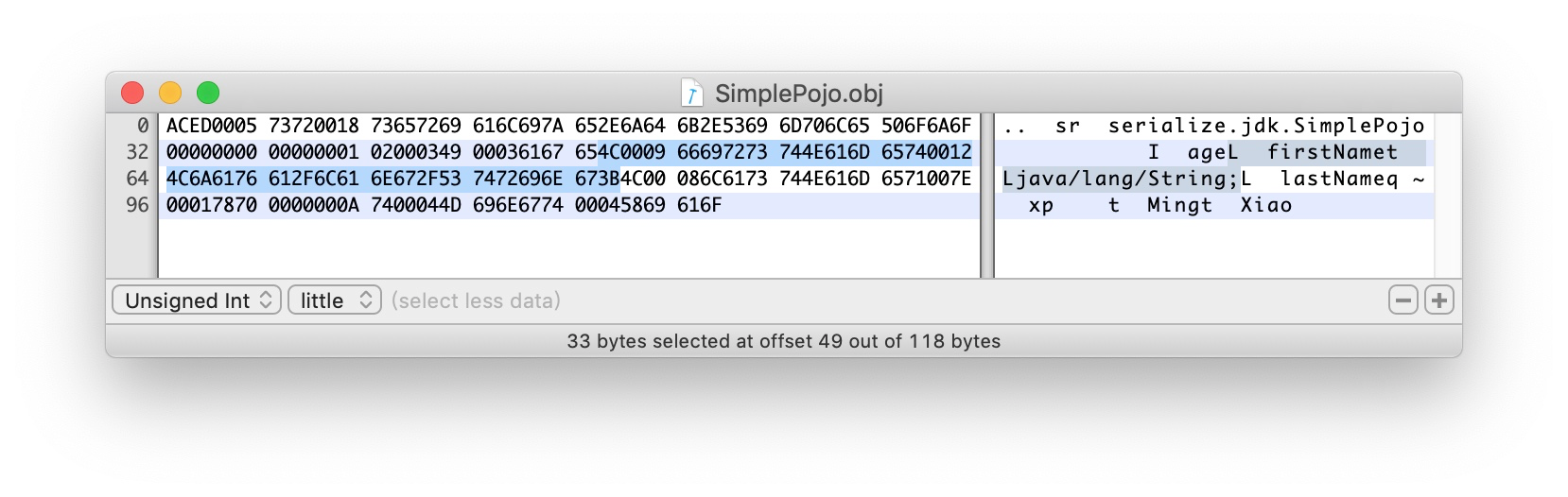
4C - L 对象类型
0009 字段名长度9字节
接下来是9个字节的字段名 firstName
74 TC_STRING 表示是一个String
0012 String类描述符长度 18
接着18个字节为 Ljava/lang/String;
接着是第三个filed:
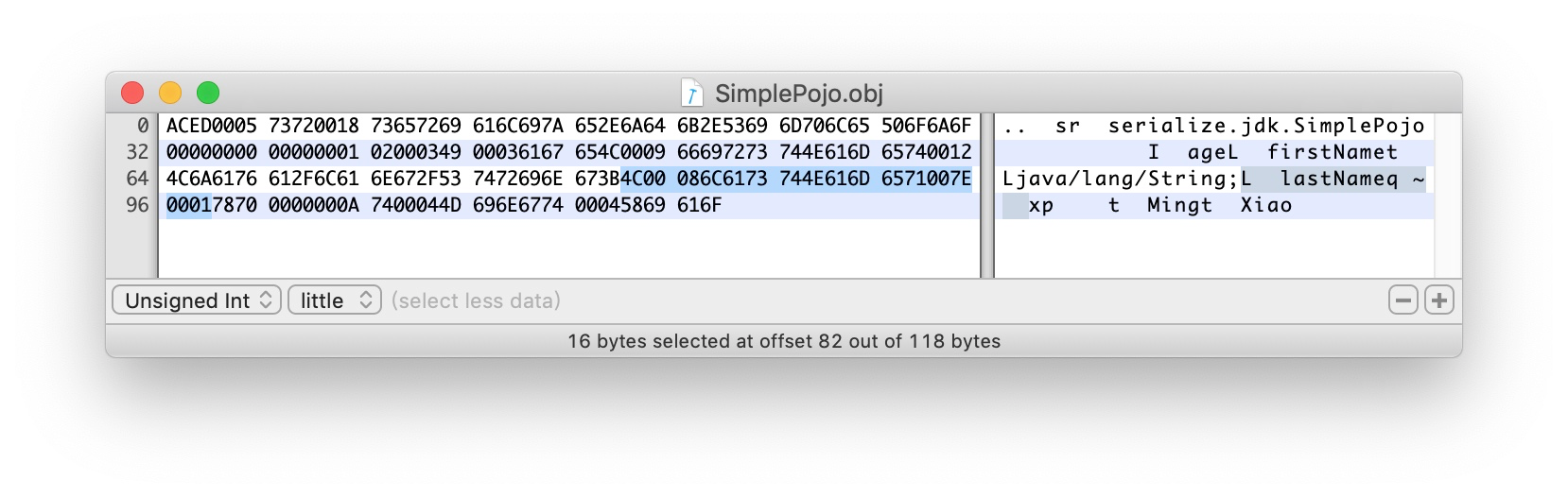
4C - L 对象类型
0008 字段名长度8字节
接下来是8个字节的字段名lastName
71 TC_REFERENCE 表示是一个指向一个已经存在的类型
007E0001 表示指向第2个field的类型(即为String)
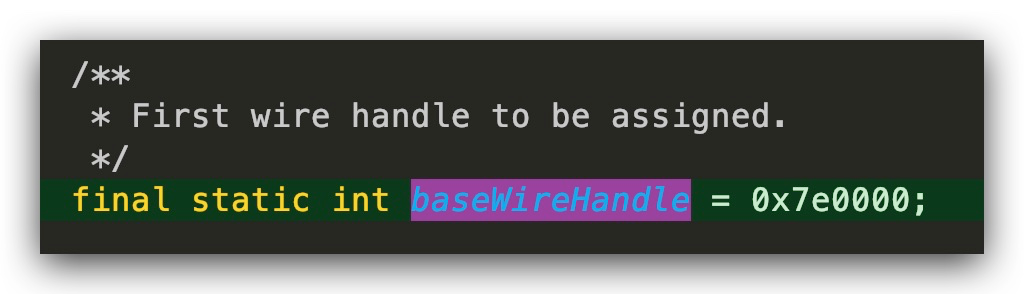
为什么007E0000表示第1个filed?
在ObjectStreamConstants中有这样一个常量,即以这个为base进行的filed计数。
78 TC_ENDBLOCKDATA 表明这一段类描述符结束(与 72 TC_CLASSDESC 表明一段类描述开始 相呼应)
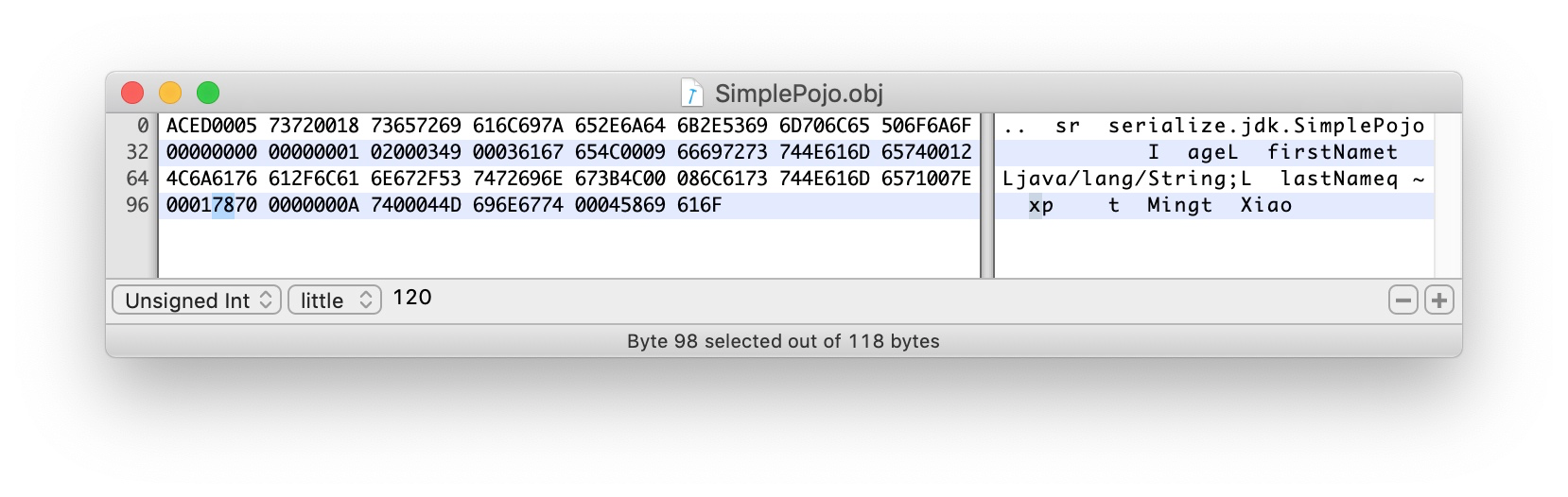
4.1.4 第四部分:父类描述
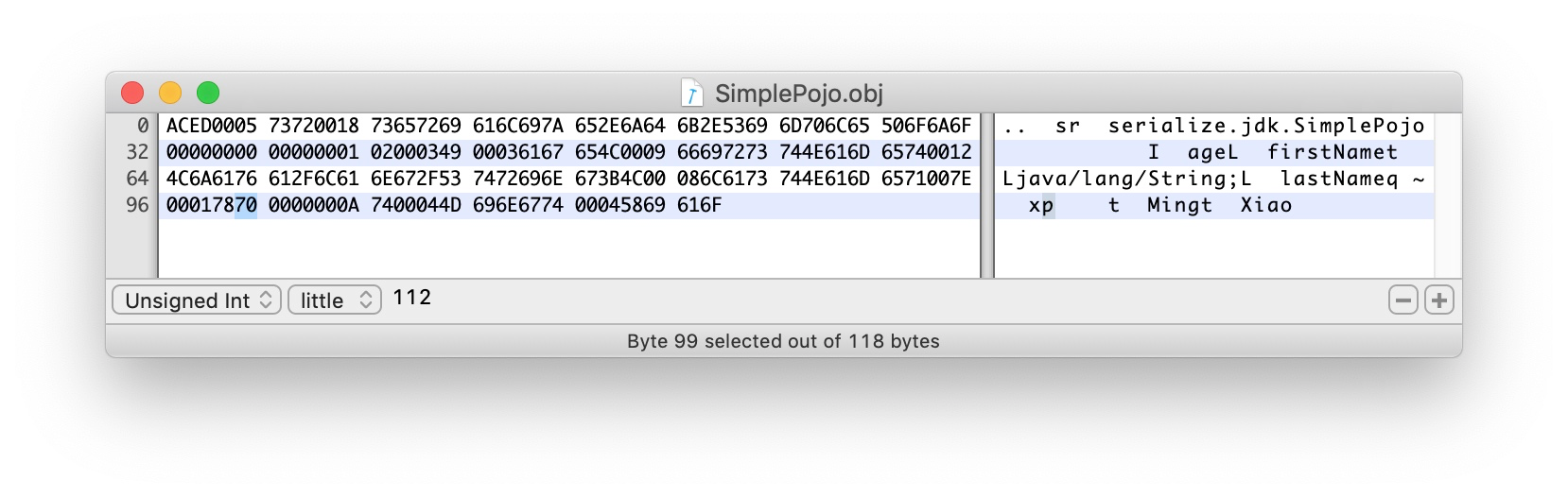
70 TC_NULL 表示没有父类,如果有,将重复上述的第三部分描述父类。
4.1.5 第五部分:filed值描述
0000000A 第一个字段值 10
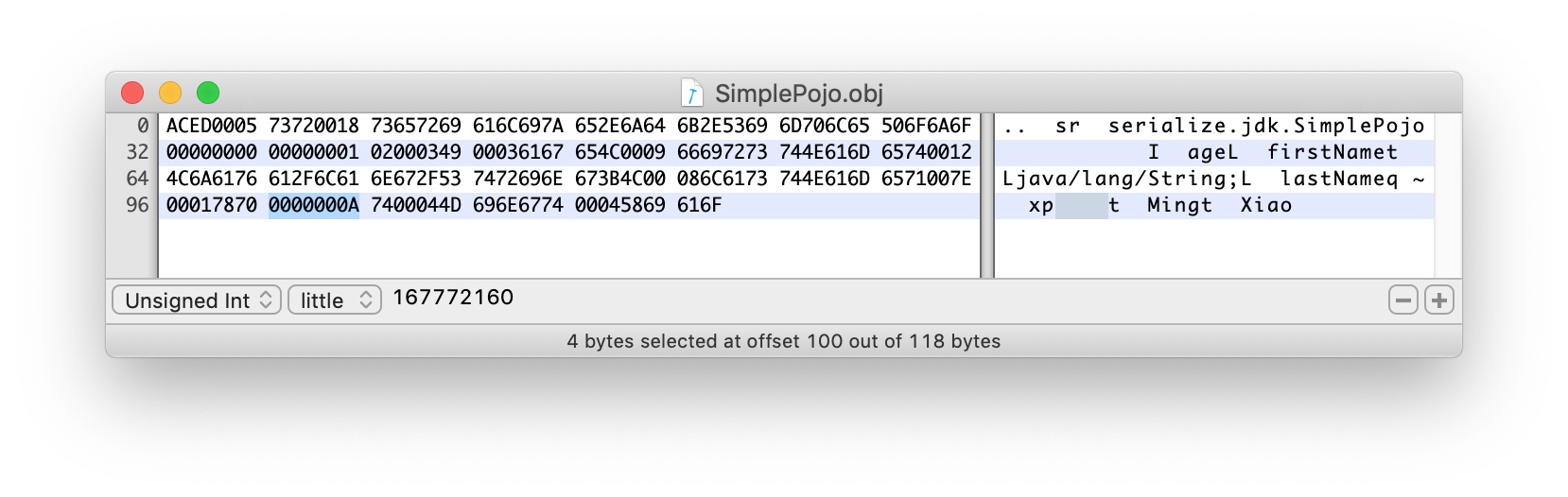
7400044D696E67 第二个字段
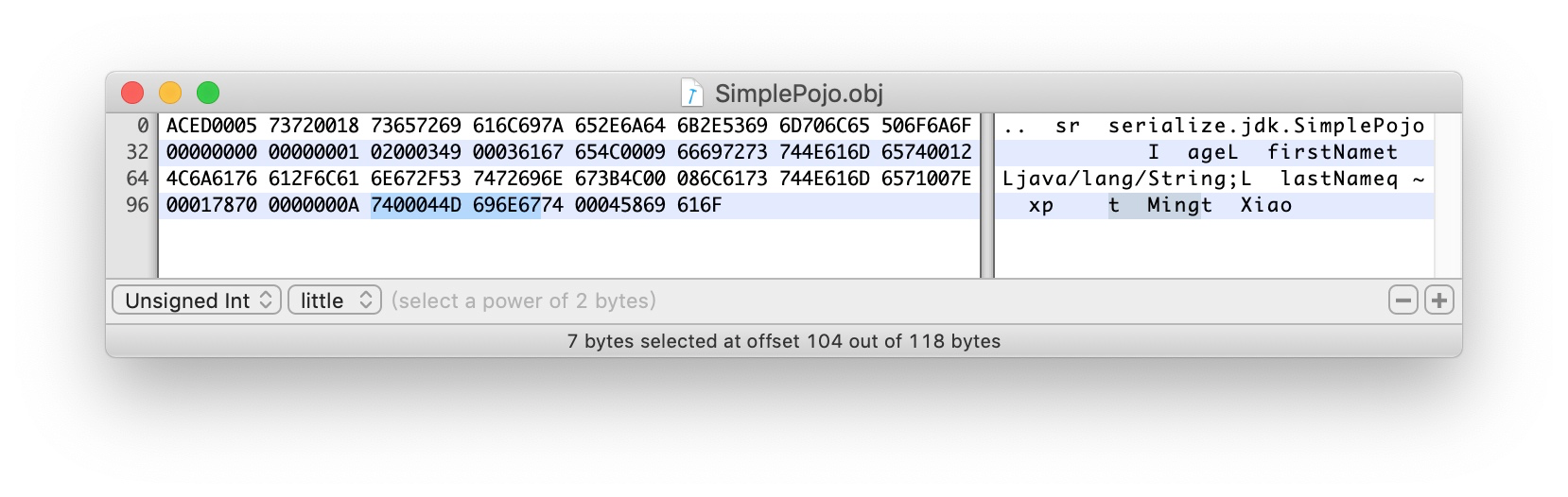
74 TC_STRING 表示是一个String
0004 长度为4个字节
接下来是个字节为String内容 Ming
4.1.6 总结
JDK源生序列化内容组织形式:
- 输出序列化的头部信息,包括序列化协议的幻数和版本;
- 基本类型按照一字节的类型标识、两字节类型长度、N个字节值
- 对象类型,第一步按照由子类到父类的顺序,递归的输出类的描述信息,知道不再有父类为止;类描述信息按照类元数据,类属性信息的顺序写入序列化流中;第二步按照由父类到之类的顺序,递归的输出对象域对象域的实际数据值;而对象的属性信息是按照基本类型到java对象类型的顺序写入序列化流中,其中java对象类型的属性会从第一步重新开始递归的输出,知道不再存在java对象类型的属性。
4.2 JDK序列化一些讨论
4.2.1 为什么空间占用大
从第二章内容可以看到,JDK序列化的内容除了必要的字段名,字段值等,含有很多类的全路径。
即通过这个二进制数据,我们基本可以完全还原这个类,包括这个类的全路径,其filed类的全路径等。这些数据占用了大量的存储空间,而这些是我们在编码中可以提供给程序的,无需序列化记录的。
4.2.2 serialVersionUID作用
serialVersionUID 是 Java 为每个序列化类产生的版本标识,可用来保证在反序列时,发送方发送的和接受方接收的是可兼容的对象。
如果接收方接收的类的 serialVersionUID 与发送方发送的 serialVersionUID 不一致,进行反序列时会抛出 InvalidClassException。
当没有显式定义 serialVersionUID 的值时,Java 根据类的多个方面(具体可参考 Java 序列化规范)动态生成一个默认的 serialVersionUID 。
serialVersionUID 就是控制版本是否兼容的,若我们认为修改的 类 是向后兼容的,则不修改 serialVersionUID;反之,则提高 serialVersionUID 的值。
因为若不显式定义 serialVersionUID 的值,Java 会根据类细节自动生成 serialVersionUID 的值,如果对类的源代码作了修改,再重新编译,新生成的类文件的serialVersionUID的取值有可能也会发生变化。类的serialVersionUID的默认值完全依赖于Java编译器的实现,对于同一个类,用不同的Java编译器编译,也有可能会导致不同的serialVersionUID。所以 ide 才会提示声明 serialVersionUID 的值。
4.2.3 Serializable接口作用
https://stackoverflow.com/questions/441196/why-java-needs-serializable-interface
4.3 自己控制序列化,Externalizable 接口
|
|
实现Externalizable接口可以自己控制java序列化策略,序列化是发现类实现了Externalizable接口,则会忽略默认的序列化/反序列化策略,执行自定义的策略。
4.3.1 一个例子:
Pojo Serializable接口,使用默认策略
|
|
PojoExternal Externalizable接口,自定义策略:
|
|
4.3.2 性能对比:
空间性能:
Pojo:176 Bytes
PojoExternal: 57 Bytes
时间性能:一百万次序列化&反序列化
Pojo:10268ms
PojoExternal: 3048ms
5.其它常见序列化协议举例
使用下面两个类作为例子
|
|
5.1 XML
IDL文件:
|
|
没有Compiler,执行代码为各语言自己的XML操作lib。
5.2 JSON
JSON没有,或者说是不需要 IDL:
JSON实在是太简单了,或者说太像各种语言里面的类了,所以采用JSON进行序列化不需要IDL。
之所以会这么神奇,来自于以下原因:Associative array在弱类型语言里面就是类的概念,在PHP和Javascript里面Associative array就是其class的实际实现方式,所以在这些弱类型语言里面,JSON得到了非常良好的支持。
没有Compiler,执行代码为各语言自己的JSON操作lib。
5.3 Thrift
Thrift是Facebook开源提供的一个高性能,轻量级RPC服务框架,其产生正是为了满足当前大数据量、分布式、跨语言、跨平台数据通讯的需求。 但是,Thrift并不仅仅是序列化协议,而是一个RPC框架。相对于JSON和XML而言,Thrift在空间开销和解析性能上有了比较大的提升,对于对性能要求比较高的分布式系统,它是一个优秀的RPC解决方案;但是由于Thrift的序列化被嵌入到Thrift框架里面,Thrift框架本身并没有透出序列化和反序列化接口,这导致其很难和其他传输层协议共同使用(例如HTTP)。
IDL文件:
|
|
有自己的Compiler,能生成可执行代码。
5.4 Protobuf
Protobuf 是 Google 开发的一种数据交换的序列化协议,性能非常高,大部分 IM 通讯协议都是使用它来传输,例如支付宝、微信等 APP。
IDL文件:
|
|
有自己的Compiler,能生成可执行代码。
6.Protobuf 使用及分析
6.1 安装Protobuf
|
|
6.2 Protobuf 使用
6.2.1 编写 gps_data.proto 描述文件
|
|
6.2.2 执行下面命令编译生成 Java 代码
- 执行下面命令编译生成 Java 代码
- -I 后面是 proto 文件所在目录
- –java_out 后面是 java 文件存放地址
- 最后一行是 proto 文件名称
protoc -I=src/main/resource/proto –java_out=src/main/java gps_data.proto
6.2.3 在项目中引入maven依赖
|
|
6.2.4 使用进行序列化与反序列化
|
|
6.3 性能对比
6.3.1 空间性能
Json:170 Bytes
Protobuf:50 Bytes
6.3.2 时间性能
一百万次序列化&反序列化
Json:使用Jackson 3881 ms
Protobuf:661ms
6.4 Protobuf简要分析
6.4.1 把数据变小一点
下面以json数据为基础出发,通过一步一步的对它进行优化,来理解protobuf的实现原理。
对于一条信息,json的表示方式为:
|
|
显然,中间有很多冗余的字符,比如{,”等,为了把数据变小一点,我们可以暴力一点,直接表示为:
30zhangsan175.33140
通过直接将value拼在了一起,舍去了不必要的冗余字符,我们大幅度的压缩了空间,但是会有一些问题,就是当我们将这段数据发送给接收端,接收端怎么知道每个value对应哪个key呢?比如zhangsan这个值,对应的是age还是name呢?
比较好的方式是事先跟接收端约定好有哪些字段,顺序是啥样子的,然后接收端按照顺序对应起来:
字段1:age字段2:name字段3: height字段4:weight↓↓↓↓30zhangsan175.33140
6.4.2 能不能更小一点
假设height这个字段为null,我们其实是不必要传递这个字段的,这个时候我们需要传递的数据就为:
30zhangsan140
但是在接收端,解析数据并按照顺序进行字段匹配的时候就会出问题:
字段1:age字段2:name字段3: height字段4:weight↓↓↓↓30zhangsan140
显然已经乱套了,为了保证能够正确的配对,可以使用tag标记:
age|30name|zhangsanweight|140
tag能减少为空(默认值)的字段的开销,但是又基本退化为json的key-value形式,tag也会占用不少的空间。
6.4.3 减少Tag的开销
json中的key是字符串,每个字符就会占据一个字节,所以像name这个key就会占据4个字节,但在protobuf中,tag使用二进制进行存储,一般只会占据一个字节,它的代码为:
|
|
fieldNumber表示后面的value所对应的字段的编号是多少,比如fieldNumber为1,就表示age,如果为2,就表示name等;wireType表示value的数据类型,以此来计算value占用字节的大小。
在protobuf当中,wireType可以支持的字段类型如下:
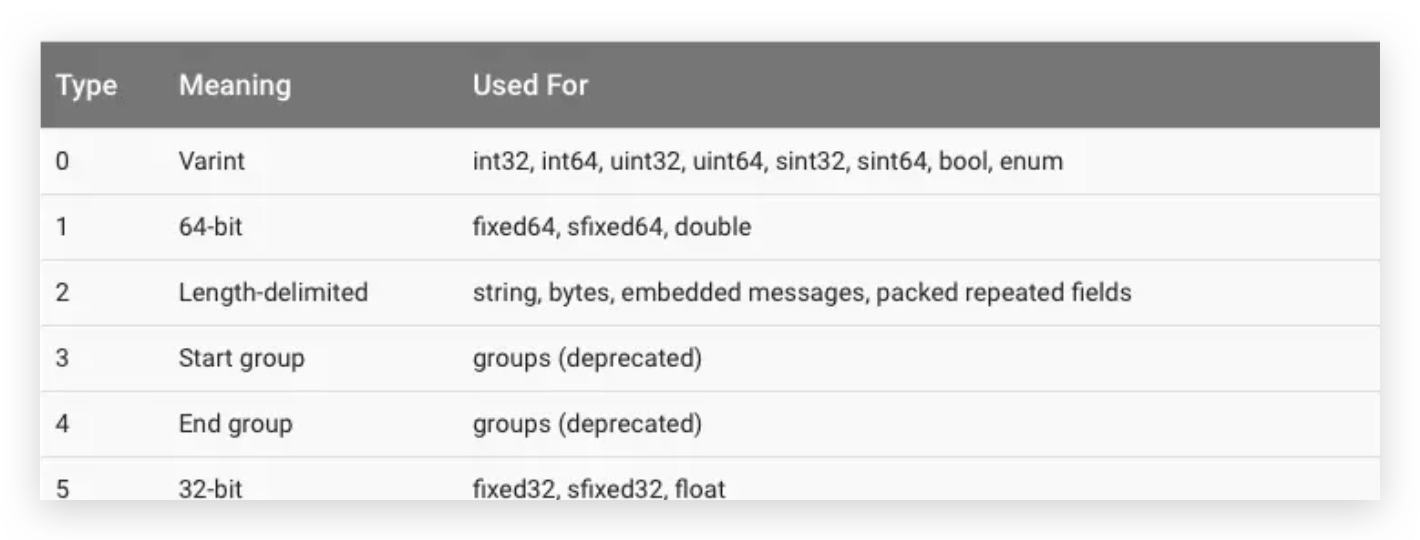
因为tag一般占用一个字节,开销还算是比较小的,所以protobuf整体的存储空间占用还是相对小了很多的。
6.4.4 优化编码
像127这种数,在计算机中的二进制是:
00000000 00000000 00000000 01111111(4字节32位)
完全可以用最后1个字节来进行存储,protobuf当中定义了Varint这种数据类型,可以以不同的长度来存储整数,将数据进一步的进行了压缩。
但是这里面也有一个问题,在计算机当中的负数是用补码表示的,对于-1,它的二进制表示方式为:
11111111 11111111 11111111 11111111(4字节32位)
显然无法用1个字节来表示了,但-1确实是一个比较简单的数,这个时候就可以使用zigzag算法来对负数进行进一步的压缩,最终我们可以使用2个字节来表示-1。
6.4.5 为什么快
因为每个字段都是用tag|value来表示的,在tag中含有value的数据类型的信息,而不同的数据类型有不同的大小,比如如果value是bool型,我们就知道肯定占了一个字节,程序从tag后面直接读一个字节就可以解析出value,非常快,而json则需要进行字符串解析才可以办到。
6.4.6 字符串怎么办
如果value是字符串类型的,具体value有多长,我们无法从tag当中了解到,但是如果不知道value的长度,就无法直接进行字节的截取。
为了能够快速解析字符串类型的数据,protobuf在存储的时候,做了特殊的处理,分成了三部分:tag|leg|value,其中的leg记录了字符串的长度,一般只需要一个字节,然后程序从leg后截取leg个字节的数据作为value。
7.ProtoStuff
无需IDL的java Protobuf
7.1 实现思路
上一章分析到,Protobuf之所以性能好,是因为是用compiler生成的序列化/反系列化的代码实现充分理解了数据格式,减少冗余数据的存储。而这需要归功于IDL文件及其IDL compiler。
但回头一想,我们的一个java bean也是充分具有每个field的类型信息的,为什么不能把 IDL文件经过编译生成可执行代码 的过程放在运行时进行了。通过反射分析一个javabean,得到这个类的描述信息,从而在序列化和反序列的时候提供支持。这样既保留了Protobuf的高性能,有不需要进行为每个类写IDL,编译,使用可执行代码等操作。
7.2 Protostuff 使用
于是就有了根据这个思路实现的 Protobuf(https://protostuff.github.io/)。
使用时候,需要提前根据目标对象生成一个对应的RuntimeSchema,序列化与反序列化的时候都需要传入这个schema进行操作。
典型代码
|
|
7.3 性能对比
7.3.1 空间性能
Protobuf:50 Bytes
Protostuff:69 Bytes
7.3.2 时间性能
一百万次序列化&反序列化
Protobuf:661ms
Protostuff:959 ms